Threat Modeling Using DeepSeek-R1 and RAG

Introduction
Intrigued by DeepSeek-R1’s reasoning capabilities, I wanted to explore its potential for automated security assessments. This simple project focuses on building a threat modeling tool (inspired by StrideGPT) using DeepSeek-R1 and RAG to analyze system architectures and generate structured threat models and attack trees.
This was a practical exercise in applying generative AI to security, tackling challenges like LLM limitations, retrieval optimization, and prompt engineering. The core goal was balancing accuracy, retrieval precision, and minimizing hallucinations to produce actionable security insights.
You can find the code for this project on my GitHub.
Objective of the Tool
This threat modeling tool is designed to assist security engineers in analyzing system architectures and identifying threats using the STRIDE framework.
- Automated Threat Modeling
- Extracts security threats from Product Requirement Documents (PRDs).
- Classifies threats under STRIDE (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege).
- Maps threats to OWASP Top 10 (2021) categories.
- Provides actionable remediation strategies.
- Attack Tree Generation
- Creates Mermaid.js attack tree representations.
- Models logical attack paths.
- Visualizes exploit chains.
- Future Enhancements
- Context-aware chat: Enables users to query the generated threat model.
- Multi-agent LLMs: Employs specialized agents for threat modeling and attack tree generation.
- DFD integration: Automates trust boundary detection and DFD generation.
Technical Architecture
The tool employs a modular RAG-based architecture to ensure contextual accuracy and structured output.
Document Processing & Embedding Generation
- File Upload: Accepts PRD documents (PDFs).
- Text Extraction: PDFPlumber extracts structured content.
- Semantic Chunking: LangChain’s SemanticChunker segments meaningful document sections.
- Vectorization: FAISS indexes the document using HuggingFaceEmbeddings.
Retrieval & Querying
This stage is critical for grounding the LLM in the provided document context. We use LangChain’s SemanticChunker to break down the PRD into meaningful chunks, which are then embedded using HuggingFaceEmbeddings.
from langchain_experimental.text_splitter import SemanticChunker from langchain_community.embeddings import HuggingFaceEmbeddings embedder = HuggingFaceEmbeddings() text_splitter = SemanticChunker(embedder) documents = text_splitter.split_documents(docs) # 'docs' is the loaded PRD
The SemanticChunker is key here. Instead of just splitting on fixed-length chunks, it tries to preserve semantic meaning, which improves retrieval relevance. We then use FAISS for efficient similarity search.
from langchain_community.vectorstores import FAISS
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 5})Retrieving the top 5 (k=5) most similar chunks gives the LLM the most relevant information.
Next comes the prompt engineering. A well-crafted prompt is essential for guiding the LLM’s behavior. We use a template that explicitly defines the expected output format (a Markdown table), the allowed STRIDE categories, and the OWASP Top 10 list. This helps constrain the LLM and reduces hallucinations.
from langchain.prompts import PromptTemplate
threat_model_prompt = """
You are an experienced Security Architect specializing in STRIDE Threat Modeling.
Analyze security threats for the given **System Context** and **Document Context**,
strictly following the structure below.
## **System Context:**
- **Application Type:** {app_type}
- **Authentication Method:** {auth_method}
- **Platform:** {platform}
- **Internet Facing:** {is_internet_facing}
## **Document Context:**
{{context}}
## **Instructions:**
- **Strictly follow the output format below.**
- Do not provide explanations, summaries, or general security recommendations.
- Identify and analyze **each asset/component** against **all STRIDE categories** only.
- **Allowed STRIDE categories:**
- **Spoofing**
- **Tampering**
- **Repudiation**
- **Information Disclosure**
- **Denial of Service**
- **Elevation of Privilege**
- **Only use the following OWASP Top 10 (2021) categories for mapping threats:**
- **A01: Broken Access Control**
- **A02: Cryptographic Failures**
- **A03: Injection**
- **A04: Insecure Design**
- **A05: Security Misconfiguration**
- **A06: Vulnerable and Outdated Components**
- **A07: Identification and Authentication Failures**
- **A08: Software and Data Integrity Failures**
- **A09: Security Logging and Monitoring Failures**
- **A10: Server-Side Request Forgery (SSRF)**
- Consider **trust boundaries, data flows, and deployment model** in the threat assessment.
- Provide **specific and actionable remediation steps**.
- **Return the Asset Analysis Table in valid Markdown format.**
## **Asset Threat Model Table Format (Markdown)**
| Asset/Component | STRIDE Category | Threat Description | Impact | Trust Boundary Breach | OWASP Mapping | Remediation |
|----------------|----------------|---------------------|--------|----------------------|---------------|-------------|
| Example Asset | Spoofing | Unauthorized access using weak authentication | High | Yes | A1: Broken Access Control | Enforce MFA and strong authentication |
## **Additional Threat Analysis Sections (After Table)**
After the table, include the following structured threat analysis:
### **Trust Boundaries**
- Identify and list all trust boundaries.
- Define security implications of trust boundaries breached.
### **Data Flows**
- Map all data flows between components.
- Indicate which data flows cross trust boundaries.
### **Deployment Threat Model**
- Identify risks related to the deployment environment.
- Consider multi-cloud, on-premises, or hybrid deployments.
- Assess threats based on network exposure, CI/CD security, and container security.
### **Build Threat Model**
- Analyze the security of the build and release process.
- Include risks related to CI/CD pipelines, supply chain security, and software dependencies.
### **Assumptions & Open Questions**
- List assumptions made in the threat model.
- Highlight areas requiring further security validation.
**Ensure that the Markdown table is correctly formatted and followed by structured analysis as defined above.**
"""
QA_PROMPT = PromptTemplate.from_template(threat_model_prompt)This structured prompt, combined with the relevant document chunks retrieved by FAISS, forms the input to DeepSeek-R1.
from langchain.chains import RetrievalQA
from langchain_community.llms import Ollama
llm = Ollama(model="deepseek-r1") # Or your chosen LLM
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever, chain_type_kwargs={"prompt": QA_PROMPT})
result = qa({"query": "Generate a threat model based on the provided document and details."})Using RetrievalQA with the “stuff” chain type simply “stuffs” the retrieved context into the prompt. More advanced chain types could be explored for larger documents.
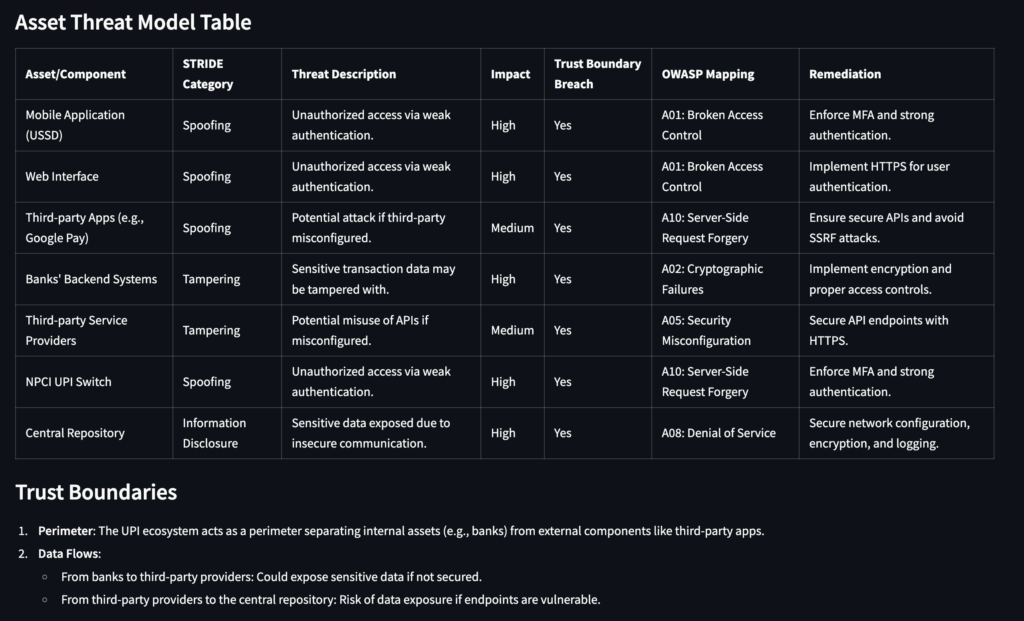
Threat Model Construction
LLM outputs a structured markdown table:
- Asset details
- STRIDE classifications
- OWASP 2021 mappings
- Trust boundary indicators
- Recommended mitigations
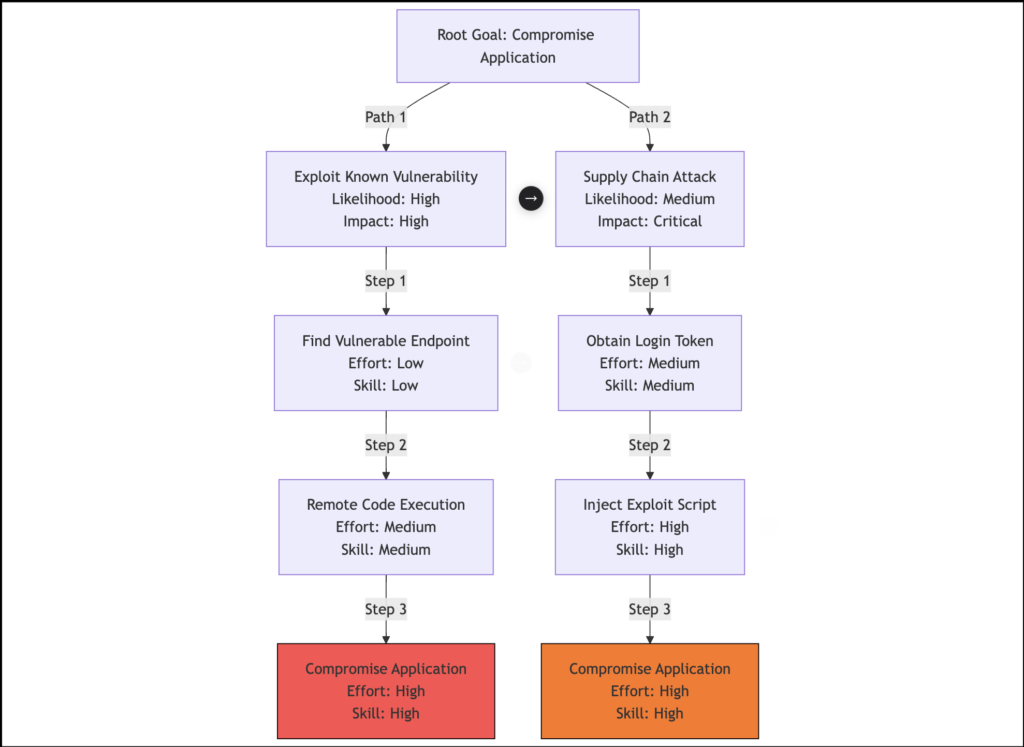
Attack Tree Generation
Since I’ve not added a feature to render the mermaid, one may use tools like MermaidFlow to visualize it.
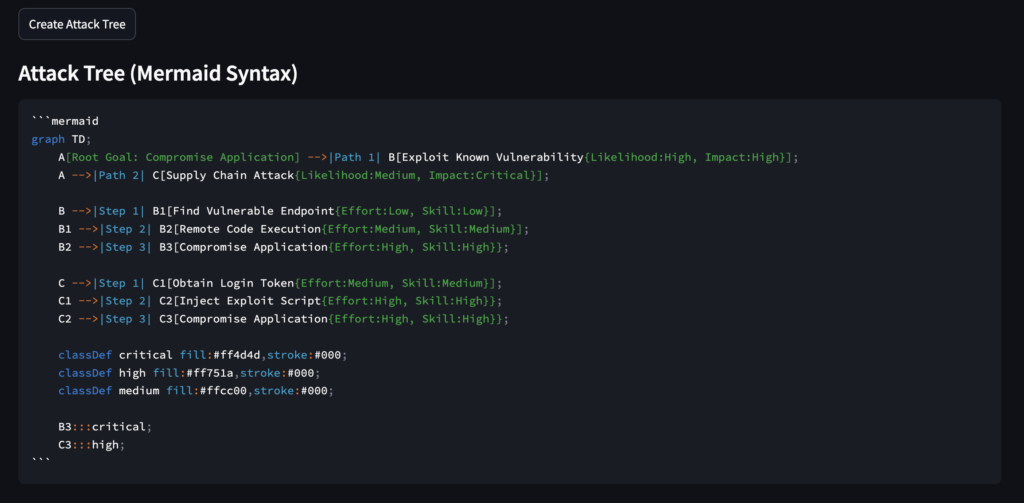
- Structured Attack Paths: Identifies logical attack flows.
- Mermaid.js Representation: Generates structured attack trees.
- Likelihood & Impact Analysis: Assigns effort, skill level, and detection difficulty to each attack step.
User Interface (Streamlit)
- File Uploader: Accepts PRD PDFs.
- User Inputs: Includes drop-downs for application type, authentication method, and internet exposure.
- Threat Model Output: Renders as a markdown table.
- Attack Tree Output: Displays in Mermaid.js syntax.
Challenges & Solutions
DeepSeek-R1, while optimized for reasoning tasks, has inherent limitations in RAG-based security analysis. Several iterations were necessary to fine-tune its behavior and mitigate hallucinations.
LLMs are like that friend who’s always got a story, even if it’s completely made up. That’s why we need RAG – to fact-check their tall tales. 😛
Common Issues and Fixes
| Issue | Solution Implemented |
|---|---|
| Incorrect STRIDE classifications | Explicitly constrained allowed STRIDE categories in the prompt. |
| Hallucinated OWASP mappings | Provided a fixed OWASP 2021 list in the prompt. |
| Invalid Mermaid.js syntax | Structured attack trees with step-wise logic. |
| Context loss in retrieval | k=5 with semantic chunking for improved recall. |
| High hallucination rate | Lowered temperature to 0.2 and tested zero-shot prompting. |
| Inconsistent outputs | Used StuffDocumentsChain to bind document context. |
Best Parameter Configuration
| Parameter | Value | Impact |
|---|---|---|
| k (retrieval depth) | 5 | Balanced precision vs recall |
| Temperature | 0.2 | Reduced hallucinations |
| Chunk Size | Adaptive (dynamic sizing) | Improved retrieval accuracy |
| Search Type | Similarity | Ensured relevant retrieval |
| Embedding Model | HuggingFaceEmbeddings | High-performance vector storage |
Results & Observations
After optimization, the model produces structured threat models and valid attack trees.
Threat Model Output
- Markdown-rendered tables.
- Assets mapped to STRIDE, OWASP, and trust boundaries.
- Actionable mitigation strategies.
Attack Tree Output
- Logical branching.
- Impact-based attack prioritization.
- Valid Mermaid.js syntax.
DeepSeek-R1 exhibits some weaknesses:
- Handling complex retrieval-based tasks.
- Overgeneralizing goals (security risks) with incomplete context.
- Occasional misclassification of threat categories.
Despite these limitations, it performs well in structured threat modeling, providing valuable security insights. The accuracy of the results is subject to the inherent limitations of LLMs, including potential hallucinations and computational constraints.
Future Enhancements
Several enhancements are planned:
- Context-Aware Chat: Enables interactive querying of the threat model and PRD document.
- Multi-Agent LLMs: Employs specialized agents for enhanced contextual awareness.
- Automated DFD & Trust Boundary Mapping: Converts threat models into DFDs, highlighting trust boundaries and risk zones.
- Integrate more Frameworks: Frameworks like DREAD, PASTA may also be integrated.
- Improved Mermaid.js Rendering: Enables direct graph visualization within the Streamlit application.
Key Takeaways
This project yielded valuable insights into AI-driven security tooling:
- Prompt Engineering is Critical: LLM behavior requires constraint with explicit rules.
- Parameter Tuning Matters: Retrieval settings and temperature significantly impact accuracy.
- Structured Output Reduces Hallucination: Markdown tables and fixed lists help anchor responses.
- RAG Pipelines Need Optimization: Context-aware chunking improves retrieval precision.
Conclusion
This weekend project was a fascinating exploration of DeepSeek-R1’s capabilities for security threat modeling. While DeepSeek-R1, even with RAG, still faces challenges – hallucinations and context handling are definite hurdles – this experiment underscored the transformative potential of generative AI for security. It’s about empowering, not replacing, human expertise. This project, focused on automating key processes like threat modeling and attack tree generation, represents both the immense potential and the remaining challenges in applying generative AI to real-world security workflows.
PS: I’d like to thank my LLM for co-authoring this blog post… and for not hallucinating too many times. xD

